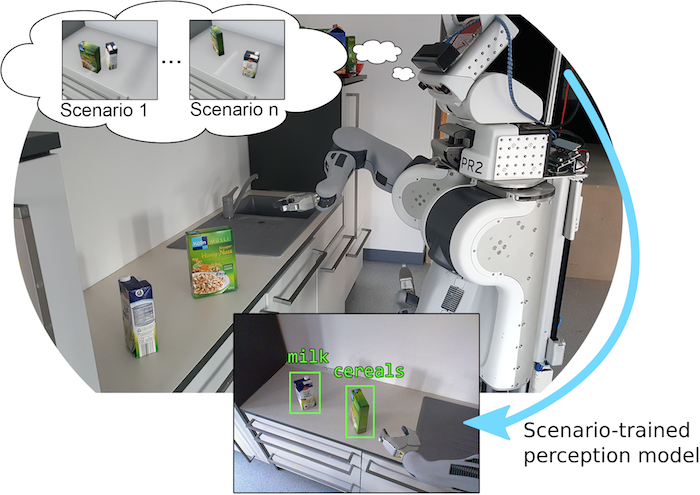
The development of high-performance perception for mobile robotic agents is still challenging. Learning appropriate perception models for everyday activities usually requires extensive amounts of labeled training data that ideally follows the same distribution as the data an agent will encounter in its target task. Recent developments in gaming industry led to game engines able to generate photorealistic environments in real-time, which can be used to realistically simulate the sensory input of an agent.
We developed a novel framework which allows the definition of different learning scenarios and instantiates these scenarios in a high quality game engine where a perceptual agent can act and learn in. The scenarios are specified in a newly developed scenario description language that allows the parametrization of the virtual environment and the perceptual agent. New scenarios can be sampled from a task-specific object distribution that allows the automatic generation of extensive amounts of different learning environments for the perceptual agent, leading to more robust perception models in human environments.
Training data and matching task distribution
Over the last decade, many impressive machine learning approaches have been developed that pushed the performance of computer vision significantly. Neural Network based approaches have reached a high level of accuracy due to very complex networks like the Resnet152 (He et al. 2016) which has 152 layers of trainable parameters. Another important foundation of the success of these models is also the quality of the training data. Even though large public, labelled image data sets are available for training, many of these datasets are not captured with a robotics background in mind. By scraping websites like FLICKr, Pexels, Facebook or Wikimedia, one gets many images that are carefully composed and might even be stylized in the way that the presentation is more appealing to the eye of a human. In Robotics, one usually gets very different pictures because the viewpoints are different or they are facing scenes that might not be of photographic interesting and are therefore not included in image databases. Another characteristic that might also not keep captured is how the same object changes it appearances over the course of time. Take for example the following images showing different plates.

If a robot is supposed to prepare a table for having a dish and afterwards clean up, it might see the same object in very different ways. When getting the stored plates out of the cabinet, it will see plates as a very thin object, while being placed on a table it appears as an almost perfect circle. When cleaning up, the plate is again changing its appearance because there may be leftovers or cutlery placed onto it.
One solution to capture these different scenarios would be to take many images from the different stages of the robot task and manually label them according to the requirements of the machine learning method employed. This task would be very laborious and very time consuming. To circumvent that problem, we propose to create virtual environments were the creation of suitable training data can be done automatically. Three crucial steps for such a system would be: a) That the objects can be placed automatically in a meaningful way, e.g. being placed as they would be in reality b) the viewpoints of the images are matching the viewpoints of the robot executing the intended tasks and c) that the gathered images are photorealistic so that the trained computer vision model can be employed on real world scenario.

The relevant object models must be available as 3d models with realistic textures. With the recent success of powerful photogrammetry software or specialized hardware for 3d scanning, the process of creating this models is greatly reduced nowadays.
Architecture
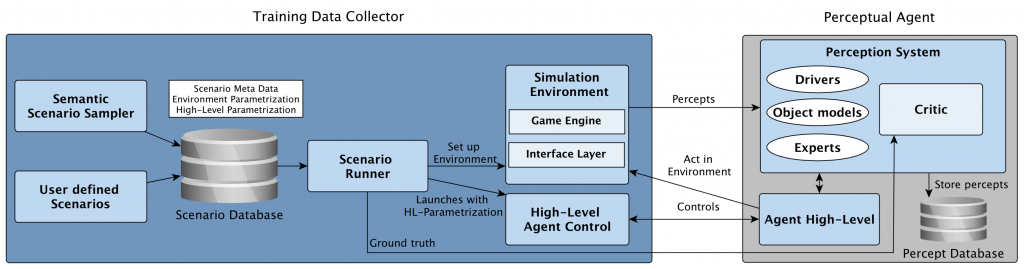
The main component of the system is the Training Data Collector .This module orchestrates the training process between different submodules. Each learning environment is represented as a Scenario. Each Scenario contains information about the static properties of the environment such as fixed furniture or the room structure. To represent the dynamics of the objects of interests in the environment, we employ probabilistic models that are sampled to decide if and where objects are placed in the environment. This information is then also encoded in the Scenario alongside a parametrization of the high-level program of the employed robot in the target domain. The last step is necessary to incorporate the control characteristics and the resulting viewpoints of the target robot and recreate this in the virtual learning environment. The latter will also be called ‘Simulation Environment’ from now on.
The simulation environment is featuring two components: First, a game engine that is capable of simulating photorealistic environments and returning labelled RGBD sensor data. Second, an interface layer that integrates the game engine with the rest of the system. The core of this interface is open source and can be accessed here: https://github.com/code-iai/ROSIntegration.
In our approach, we have selected the game engine Unreal Engine 4 as it features capabilities to render photorealistic scenery in realtime, provide labelled RGBD sensor data (Qiu, Alan 2016) and simulate physics to simulate robotic systems.
The Scenario Runner will finally bring the different components together: It loads a given set of Scenarios, instantiates them in the Simulation environment and starts the High-Level Control Program with the corresponding Parametrization from the Scenario.
The virtual percepts can then be used in a perception system to guide the high-level plan execution and the gathering of the labelled object data for training. In our approach, we have used RoboSherlock (Beetz et al. 2015) as the perception system because it features drivers to interface with virtual sensor data from Unreal Engine and it integrates multiple perception experts well.
Results & Future Work
With the outlined system, we were able to train object recognition models purely on virtual sensor data that are then successfully used on a robot in a real world task. By using an ImageNet-CNN as a feature generator, we collected training data from the simulation environment which is then stored in a datastructure for fast nearest-neighbor search. Every new incoming percept of the robot in the real world is fed through the same Neural Network and matched to the previously stored training inputs to generate an recognition hypothesis. For more information on the experiments and the methodology, we kindly ask you to look into the relevant publication at the bottom of this page.
In future work, we want to expand the capabilities of this system in such a way that it is possible for robots to hallucinate the outcome of manipulation actions in a visual manner. In addition to the generated imagery, we also want to combine these hallucinations with semantics to be able to explain and reason about differences in the hallucinated and in the real outcome after executing an action.
Relevant publication:
Mania, Patrick, and Michael Beetz. “A Framework for Self-Training Perceptual Agents in Simulated Photorealistic Environments.” 2019 International Conference on Robotics and Automation (ICRA). IEEE, 2019.
Access it here: https://ieeexplore.ieee.org/document/8793474
Citations:
Beetz, Michael, et al. “Robosherlock: Unstructured information processing for robot perception.” 2015 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2015.
He, Kaiming, et al. “Deep residual learning for image recognition.” Proceedings of the IEEE conference on computer vision and pattern recognition. 2016.
Qiu, Weichao, and Alan Yuille. “Unrealcv: Connecting computer vision to unreal engine.” European Conference on Computer Vision. Springer, Cham, 2016.