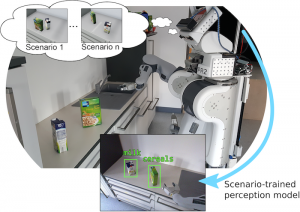
Robots acting in real-world environments, such as human households, require a vast amount of various knowledge to be able to execute their tasks. For example, consider the task of setting a table for breakfast. The robot needs to know which objects are involved in the task, where to find them in the given environment, how to stand to have an object in the field of view, how to grasp objects, where to stand to be able to reach them, what is the appropriate table setting configuration in the particular context, etc.
This knowledge is difficult to obtain. One natural way to do this is to learn from human demonstrations. Virtual reality (VR) technology nowadays is getting very popular and easily accessible. VR systems allow humans to interact with a virtual environment in a natural and intuitive way. Logged data of humans executing tasks in VR is a powerful source of everyday activity knowledge that can be used to teach robots. VR systems allow to easily vary the environment and task scenarios, provide highly accurate ground truth data and give access to the underlying world physics.
We implemented an approach for transferring symbolic and subsymbolic data acquired from VR human data onto the robot and for adapting it accordingly to achieve successful task execution (see the Figure above). This requires to solve the correspondence problem between the observed actions and robot actions, and to transform the observed data into executable one. The data cannot be transferred as is, due to the differences between the virtual and the real environments and the objects in them, the physical bodies and the capabilities of robots and humans, and the contexts of tasks performed in VR and the real world.
We demonstrate our pipeline by inferring seven parameters of a general mobile pick and place action, including semantic information such as that bowls should be grasped from the top side, and subsymbolic data such as geometric arrangements of objects on a table for setting it for a meal. We prove that the transferred data is of high quality and enables the robot to execute a mobile manipulation task of setting a set a simple breakfast table in a real world kitchen environment.
Acquiring Data by Observing Humans in VR
Our data acquisition pipeline is as following:

- The human is tasked in natural language to perform a certain action, for example, to set a table for breakfast and then clean up.
- While the human performs the actions, we automatically log everything that is happening, including
- subsymbolic data such as human motion trajectories and object poses, and
- symbolic data, including performed actions and the events that happened, as well as the semantic representation of the environment.
Parameters of Mobile Pick and Place Actions
In general, any mobile pick and place action is comprised of three main sub-actions: search for the object in the given environment, fetch it and then deliver it at the desired destination. The parameters of these actions are:
- search:
- object-likely-location: location where we are likely to find the object
- base-location-for-perceiving: the pose for the robot to stand such that the object likely location is well visible
- fetch:
- arm: with which arm to grasp the object, if the robot has multiple arms
- grasp-pose: what should be the position and the orientation of the fingers with respect to the object
- base-location-for-grasping: where to stand to grasp with the given grasp pose and the given arm
- deliver:
- object-destination-location: the desired destination in the given context for the given object
- base-location-for-placing: where to stand such that the destination location is within reach
We learned all seven of these parameters with our VR-based pipeline.
Data Transfer and Learned Models
To parameterize the robot actions, we look up the corresponding action parameters that the human used in VR. But because we have to deal with environment discrepancies, we do not use absolute coordinates but the relative ones.
Once we have the locations from humans in the virtual environment ported to the robot environment, we can learn a generalized model that fits these samples into a distribution specific to our robot platform.
Below a distribution for robot base poses is visualized as heat maps: these are poses for the robot to stand for grasping the bowl.

Results and Future Work
For collecting the data in VR, we designed four different kitchen environments in our game engine. One of these kitchens was quite similar to the robot’s real-world kitchen:

and the other three had different scale, position and orientation of the furniture pieces, as shown on an example below:

Then we performed 14 different types of experiments, which differed in the following:
- The robot body that was used to set the table: we had Boxy and PR2 in simulation and the PR2 in the real world.
- The environment of the robot: we had a precise model of the real-world kitchen in our simulation and we also made a variation of that, where the furniture pose were changed, to test scalability towards new environments.
- We wanted to compare the performance of our approach to some baseline, so we hand-crafted specialized heuristic reasoners for inferring each of the parameters of the mobile pick and place actions. Thus, we performed experiments with both our VR-based inference engine and with the heuristics-based engine and compared the two.
- We also varied the VR data batches, to see how the data affects the robot’s performance.
Our experiments showed that our approach is feasible and allows the robot to successfully perform a simple table setting task. They also showed that the system scales to a certain extent to different robot bodies and new robot environment arrangements.
For the next iteration of this line of work, we would like to circumvent the problem of mapping between the human and robot bodies by directly controlling a robot body inside VR. We also find that our evaluation scenario was a bit too simple, so we would like to add taking objects out of containers, such as drawers or cupboards, and, perhaps, add more complex manipulation actions such as pouring or cutting.
For more details on the described system, we kindly ask you to take a look at the relevant publication.
Relevant publication:
Gayane Kazhoyan, Alina Hawkin, Sebastian Koralewski, Andrei Haidu and Michael Beetz, “Learning Motion Parameterizations of Mobile Pick and Place Actions from Observing Humans in Virtual Environments”, In IROS, 2020.
Access it here: https://ieeexplore.ieee.org/document/TODO